|
I am a research assistant at the Computer Vision Center at the Iran University of Science & Technology. I graduated with a master's degree in Electrical Engineering in 2021, which was being conducted under the supervision of Prof. Shahriar Baradaran Shokouhi. My long-term research goal is to enable AI agents to explain phenomena beyond low-level statistics of observable data. Email: omid.nejaty@gmail.com Researh Interest
|

|
|
|

|
Omid Nejati Manzari, Shahriar B Shokouhi International Conference on Computer and Knowledge Engineering , 2021 In This paper proposes a network that uses residual blocks in the network to obtain a top-1 accuracy of 99.51 for the German traffic sign recognition benchmark. The number of parameters is ∼430,000, which is ∼32x fewer than the state-ofthe-art. Experiments have been performed to show the network's resistance to destructive factors and its comprehensiveness in the application of traffic sign recognition. These tests show that it is a comprehensive and robust network for the recognition of traffic signs. |

|
Omid Nejati Manzari, Amin Boudesh, Shahriar B Shokouhi International Conference on Computer and Knowledge Engineering , 2022 We observed that vanilla ViT could not yield satisfactory results in traffic sign detection because the overall size of the datasets is very small and the class distribution of traffic signs is extremely unbalanced. To overcome this problem, a novel Pyramid Transformer with locality mechanisms is proposed in this paper. Specifically, Pyramid Transformer has several spatial pyramid reduction layers to shrink and embed the input image into tokens with rich multi-scale context by using atrous convolutions. Moreover, it inherits an intrinsic scale invariance inductive bias and is able to learn local feature representation for objects at various scales, thereby enhancing the network robustness against the size discrepancy of traffic signs. The experiments are conducted on the German Traffic Sign Detection Benchmark (GTSDB). The results demonstrate the superiority of the proposed model in the traffic sign detection tasks. More specifically, Pyramid Transformer achieves 77.8% mAP on GTSDB when applied to the Cascade RCNN as the backbone, which surpasses most well-known and widely-used state-of-the-art models. |
|
Omid Nejati Manzari, Hossein Kashiani, Shahriar B. Shokouhi Engineering Science and Technology, an International Journal , 2023 In this paper, we explore the robustness of vision transformers against adversarial perturbations and try to enhance their robustness/accuracy trade-off in white box attack settings. To this end, we propose Locality iN Locality (LNL) transformer model. We prove that the locality introduction to LNL contributes to the robustness performance since it aggregates local information such as lines, edges, shapes, and even objects. In addition, to further improve the robustness performance. |
|
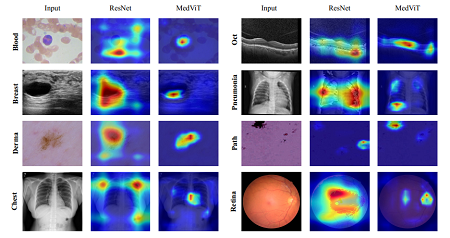
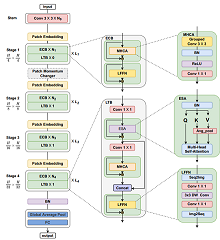
Omid Nejati Manzari, Hamid Ahmadabadi, Hossein Kashiani, Shahriar B. Shokouhi Computers in Biology and Medicine , 2023 In this study, we propose a highly robust yet efficient CNN-Transformer hybrid model which is equipped with the locality of CNNs as well as the global connectivity of vision Transformers. To mitigate the high quadratic complexity of the self-attention mechanism while jointly attending to information in various representation subspaces, we construct our attention mechanism by means of an efficient convolution operation. Moreover, to alleviate the fragility of our Transformer against adversarial attacks, we attempt to smooth out various directions of the decision boundary. To this end, we change the shape (or style) context of different instances in the high-level feature space by permuting the feature mean and variance across different instances. With less computational complexity, our proposed hybrid model demonstrates its high robustness and generalization ability compared to the state-of-the-art studies on a large-scale collection of standardized MedMNIST-2D datasets. |
|
|
|
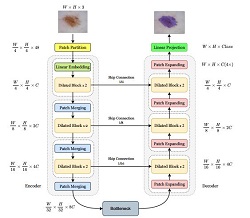
Davoud Saadati, Omid Nejati Manzari, Sattar Mirzakuchaki This paper introduces DilatedUNet, which combines a Dilated Transformer block with the U-Net architecture for accurate and fast medical image segmentation. Image patches are transformed into tokens and fed into the U-shaped encoder-decoder architecture, with skip-connections for local-global semantic feature learning. The encoder uses a hierarchical Dilated Transformer with a combination of Neighborhood Attention and Dilated Neighborhood Attention Transformer to extract local and sparse global attention. The results of our experiments show that Dilated-UNet outperforms other models on several challenging medical image segmentation datasets, such as ISIC and Synapse. |
|
|
|
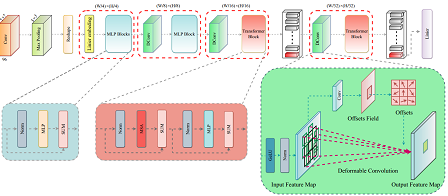
Convolutional Neural Networks (CNNs) have mainly failed to explicitly model long-range dependencies, primarily because of their intrinsic locality. To address this issue, Transformers have drawn increasing interest in exploiting long-range dependencies among input data. In this study, we aim to enjoy the merits of both local and global feature extractions in CNN and Transformer architectures. To this end, we go beyond the conventional Transformer frameworks and introduce a highly efficient Transformer architecture for early diagnosis and treatment of COVID-19 patients using CT images. |
 |
In Autonomous cars use images of the road to detect drivable areas, identify lanes, objects near the car, and necessary information. This information achieved from the road images are used to make suitable driving decisions for self-driving cars. Drivable area detection is a technique that segments the drivable parts of roads in the image. Modern methods often consider road detection as a pixel by pixel classification task, which is struggling to solve the problem of computational cost and speed. So to increase the speed of performance, we consider the process of drivable area recognition as a row-selection task. In this paper, special rows in the image are selected. Then, the boundaries of the drivable area are detected in these rows. |
|
| |
|